Cambridge, Oxford, Princeton and Yale
When comparing Webometrics with other Rankings of Universities most of the discrepancies appear related with striking web policies of the involved institutions. As we mentioned in the
FAQ, there are about 500 universities with two or more central webdomains, sometimes maintaining the old domain even after years of the official change. The bad naming practices could explain most of the unexpected (delayed) positions of world class universities but not all of them.
Cambridge, Oxford, Princeton and Yale are very prestigious organizations that should be probably amongst the Top 10 universities of the World, at least according to thousands of people from all over the world that probably never spent even a single day in their facilities. The actual performance in the XXIth century of these universities as shown by Webometrics is still very impressive but their positions are far from the Top 10.
Marketing could explain this subjective perception (Of course, how many German elite universities could you cite?), but there should be additional explanations for the delayed ranks. Our current suggestion is that the lack of large institutional repositories at Princeton and Yale explain part of the situation, but we were unable to find additional reasons.
Suggestions and comments are welcomed.
Revolutionary Road
Many of our readers believe that our objectives are to promote
Open Access and to rank Universities according to their web presence. However, the reality is slightly different as there is only one objective: Reinforce electronic publication through ranking institutions.
As probably you already know, the bibliometric evaluation procedures are in fact responsible of the explosive growth of academic publications. If "Publish or Perish" is the current motto of scholars, our efforts are intended to change it to "
Web Publish or Perish" in a nearby future.
This aim should be taken into account for understanding the recent changes in the ranking methodology. In the last year we published the web indicators as ordinals because ranks have far more impact than percentages. Contrary to other ranking editors, our composite indicator combined ranks not values, clearly favouring top universities (second is twice first, even if there is little percentage difference between them).
Now we decided to have the best of both worlds: The WR indicator is calculated with the normalized values (without changes in the weighting), but we publish the individual indicators (
size, visibility, rich files and Scholar) as ranks, as in previous editions.
Do not forget to read our new
FAQ!.
Changes scheduled for the July 2009 edition
Comments are welcomed regarding the following major changes scheduled for the next edition.
•
University of Helsinki. A 20% of the size and visibility raw numbers are taken, considering that the City Hall shares the same domain
•
Imperial College data results from combining ic.ac.uk and imperial.ac.uk
• Also in UK,
University of Manchester is ranked according to the combination of its two domains
• The three domains of the
Technical University of Munich are combined.
• The most controversial could be combining
Caltech domain with the
Jet Propulsion Laboratory one (under jpl.nasa.gov)
• The very large repositories Citeseer and CiteSeerX are excluded from the calculations related the
Pennsylvania State University• The same applies for the database DBLP regarding
University of Trier in Germany
•
Harvard Business School will be merged with
Harvard University and the former entry will be deleted.
• Johns Hopkings “extra” domains will be combined with the central one and the additional entries will be deleted
• The figures from “La Jornada” subdomain will be excluded from the UNAM statistics
• The data from the two
Cardiff University's domains will be merged
• The Jussieu campus webdomain will be merged to the UPMC and its entry deleted
•
Griffith University two domains will be combined
• The two domains of
Universität Zurich are to be combined
• New and old domains for
Ludwig Maximilians Universität Munchen will be unified.
• Same for
Technische Universität Dortmund.
• The two/three domains of these Catalonian universities will be combined:
Barcelona, Autónoma de Barcelona and Politècnica de Catalunya.
• The “universities de Strasbourg” domain (u-strasbg.fr) will have an independent entry.
• These US universities ranking will take into account previous and current domains:
Kansas State, Northeastern University, University of Illinois at Urbana-Champaign (the last one perhaps not)
• Under consideration merging the Dutch University Hospitals with their corresponding Universities
• The
City College (CUNY) will be included in the main list even without having independent domain
•
Lund Institute of Technology will be merged into
Lund University and its entry discarded
• There a few universities with faculties having fully independent domains. As there is central domain all these extra entries will be deleted but the data will not combined. Currently this applies to
University of Zagreb , Warsaw University and
Universidad de la República (Uruguay).
Major changes, Major problems
The blog is re-activated
One of the most frequent criticism the Ranking Web receive is the lower than expected ranks of very prestigious Universities. Imperial College or Technical University of Munich clearly appears delayed as compared with other Rankings.
The Ranking Web is based on an internet unit, the institutional domain. MIT domain is mit.edu and all the calculations are obtained from pages under that domain. However, a few institutions maintain more than one domain for their pages, sometimes with a secondary domain even larger than the official central one. This situation penalizes their Web performance and it is also a bad practice because affect negatively their web visibility and it is very confusing for foreign visitors.
These web policies are clearly identified in the Notes section and we expect managers try to combine all the pages under only one domain. However, in the last months we discover that important Universities are changing their domains. Most of cases the objective is to improve the "marketing" quality of the acronym, making it easy to remember or more descriptive.
There is no problem on these changes. Clearly, the Illinois University at Urbana-Champaign is better described by illinois.edu than by the older uiuc.edu. Case Western Reserve University is now case.edu instead of cwru.edu. The already mentioned Imperial College is referred as imperial.ac.uk instead of the more obscure ic.ac.uk.
So, what is the problem?. The most concerning issue about these changes is that many of them are applied to the full website very slowly, so during long periods many of the servers still maintains the old domain. The central website has the new address but other important sites, even the library and the repositories, still are available only under the old domain.
In a few cases the old domain is better ranked than the new one and we use the best positioned unit but the penalty is severe and misunderstandings are frequent.
During the last July 2008 edition a few examples are very conspicuous (new/old):
Pontificia Universidad Católica de Chile (uc.cl/puc.cl)
Thomas Jefferson University (jefferson.edu/tju.edu)
Tech. Univ. Braunschweig (tu-bs.de/tu-braunschweig.de)
Tech. Univ. Helsinki (tkk.fi/hut.fi)
Univ Mediterranee (univmed.fr/mediterranee.univ-aix.fr)
Northeastern Univ (neu.edu/northeastern.edu)
Univ Catholique de Louvain (uclouvain.be/ucl.ac.be)
Victoria Univ of Wellington (victoria.ac.nz/vuw.ac.nz)
Not my fault
When visitors check the
Webometrics Ranking of Universities, sometimes the institution they are seeking is not in the Catalogue or its classification is clearly below expected. There are several technical reasons for these situations:
Universities without independent domain name. The ranking and catalogue only include universities with their own institutional domain. More than 200 institutions worldwide are still publishing their pages in directories under the domain of their internet hosting company or other shared domain. Many African universities (Nigerian federal ones) prevent us of further WR calculation due to this limitation.
Universities with multiple institutional domains. Most universities have extra domains unrelated to main institutional one, usually devoted for specific and small impact projects or spin-offs organizations. However there some striking situations where two equally valid names are used for the same university or a large part of the sites are under another (older?) domain. It is not feasible to combine the data for the different domains and the global WR of the institution does not reflect its real impact. Two good examples are Imperial College (
ic.ac.uk, imperial.ac.uk) and St. Petersburg University (
spbu.ru, pu.ru).
Changes in the institutional domain. The use of a new domain imposes an important penalty in the calculation of several web indicators. Recent split of the Jussieu campus (jussieu.fr) of the University of Paris (now
.upmc.fr, .univ-paris7.fr and others) can be cited. Unfortunately this is fairly common situation that affects even to universities in the Top 100, but a worrisome example is changes in the name of academic subdomains of many Indian universities, that could explain their delayed positions.
Use of shared domains. Different universities and research centres share the same or similar domains in at least two groups of French Universities: Marseille (almost fixed) and Strasbourg. This situation is a bit messy and web rankings of these institutions are not reflecting their true position. A similar situation could be applied to Helsinki University which on the contrary has an overvalued rank because the city also use
helsinki.fi domain!. There is no unique domain for the Universidad de la Republica of Uruguay, so each Faculty has its own institutional domain.
Invoked on the Web
The
citation analysis is not the only way to analyze the bibliographic characteristics of a paper although it is a key method for bibliometric studies. In a similar way, some proposals intend to restrict the webometric studies to the link analysis and specifically the sitation analysis, the formal links between electronic papers. Obviously, there are many other possibilities to exploit web data, including informal references that can benefited from the large sample size of the webspace.
Cronin et al. (
Invoked on the Web. Journal of the American Society for Information Science, 49 (14): 1319-1328) in 1998 proposed to analyse the number of times a researcher’s name appeared cited in web pages. This is equally valid for a title of a paper (introduced formally by
Liwen Vaughan and used by
Hildrun Kretschmer too, the name of an institution, or selected terms or phrases (You can check some of the papers by
Judit Bar-Ilan).
From a methodological point of view, and taking into account that search engines do not cover all the Web and there important bias in their results, invocation can be calculated easily using quotation marks around the name in the search engines. The result is referred as the number of times this name is cited in the Web. Some authors call it Web visibility, although we prefer to reserve this word for link visibility. This indicator usually favours large, well-known, old institutions independently of their real effort for having a relevant Web presence.
Some Peruvian universities were chosen to compare several webometric indicators. Ranked according to the invocation, there are some placements that are not correlated with those obtained with the other indicators.
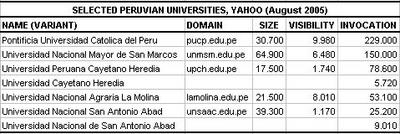
Although invocation measures can be interesting for some analysis, a cautionary use is recommended as it is not possible to assign a unique, unambiguous universal name for every institution.

